長沙多少例新型冠狀病毒seo外包資訊
目錄
- ResNet
- 總結
- ResNet代碼實現(xiàn)
- ResNet的梯度計算
ResNet

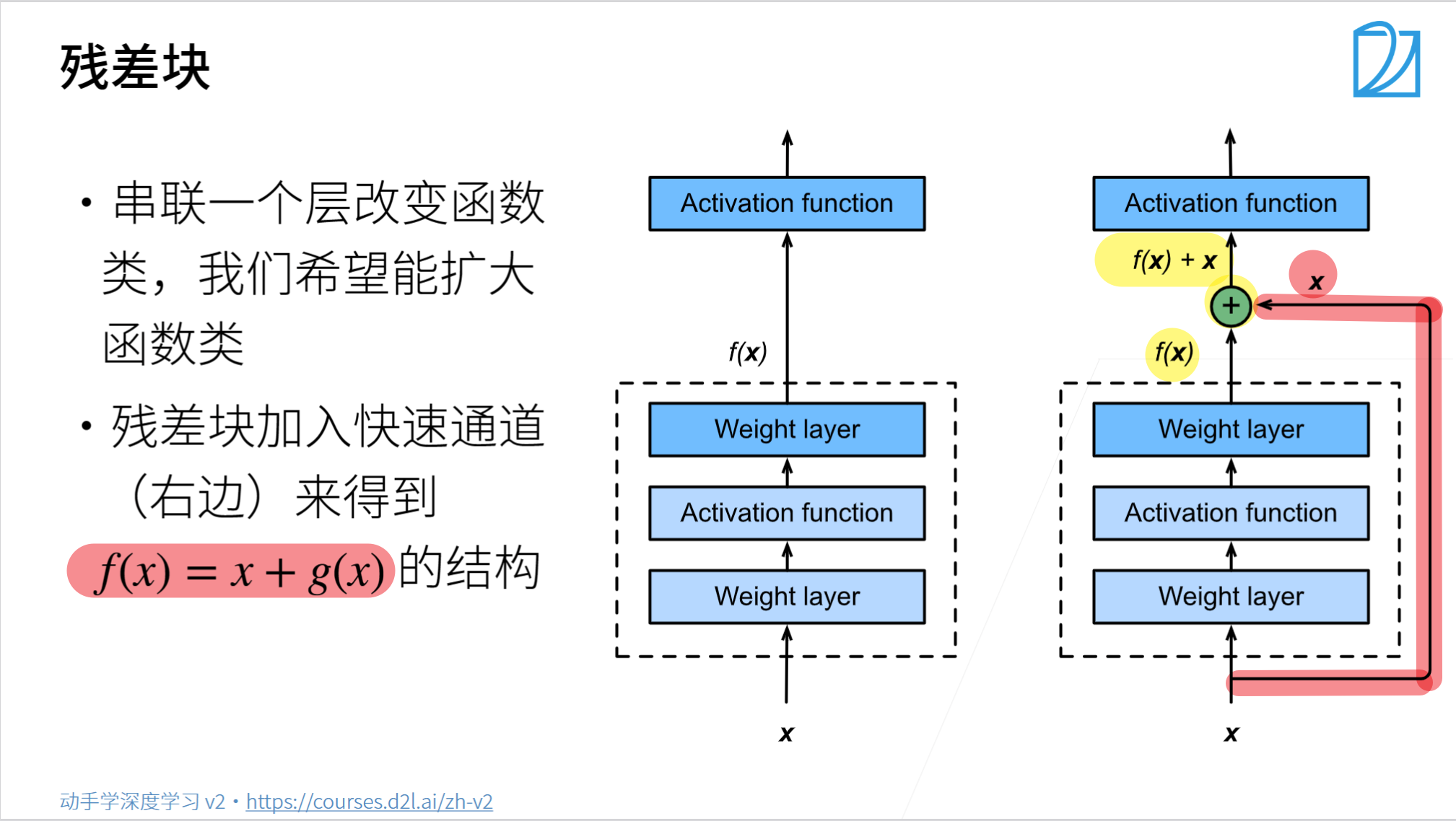
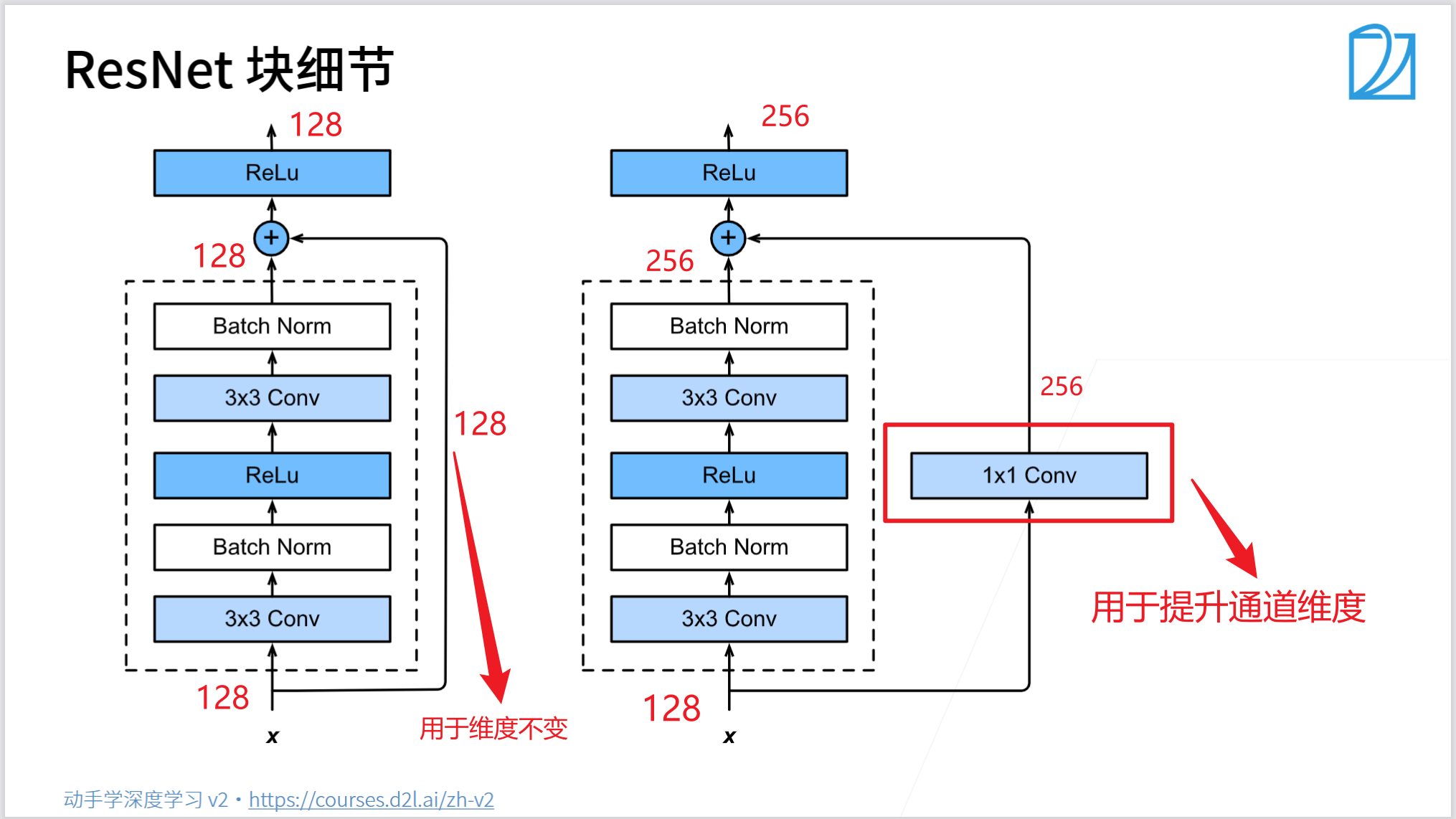
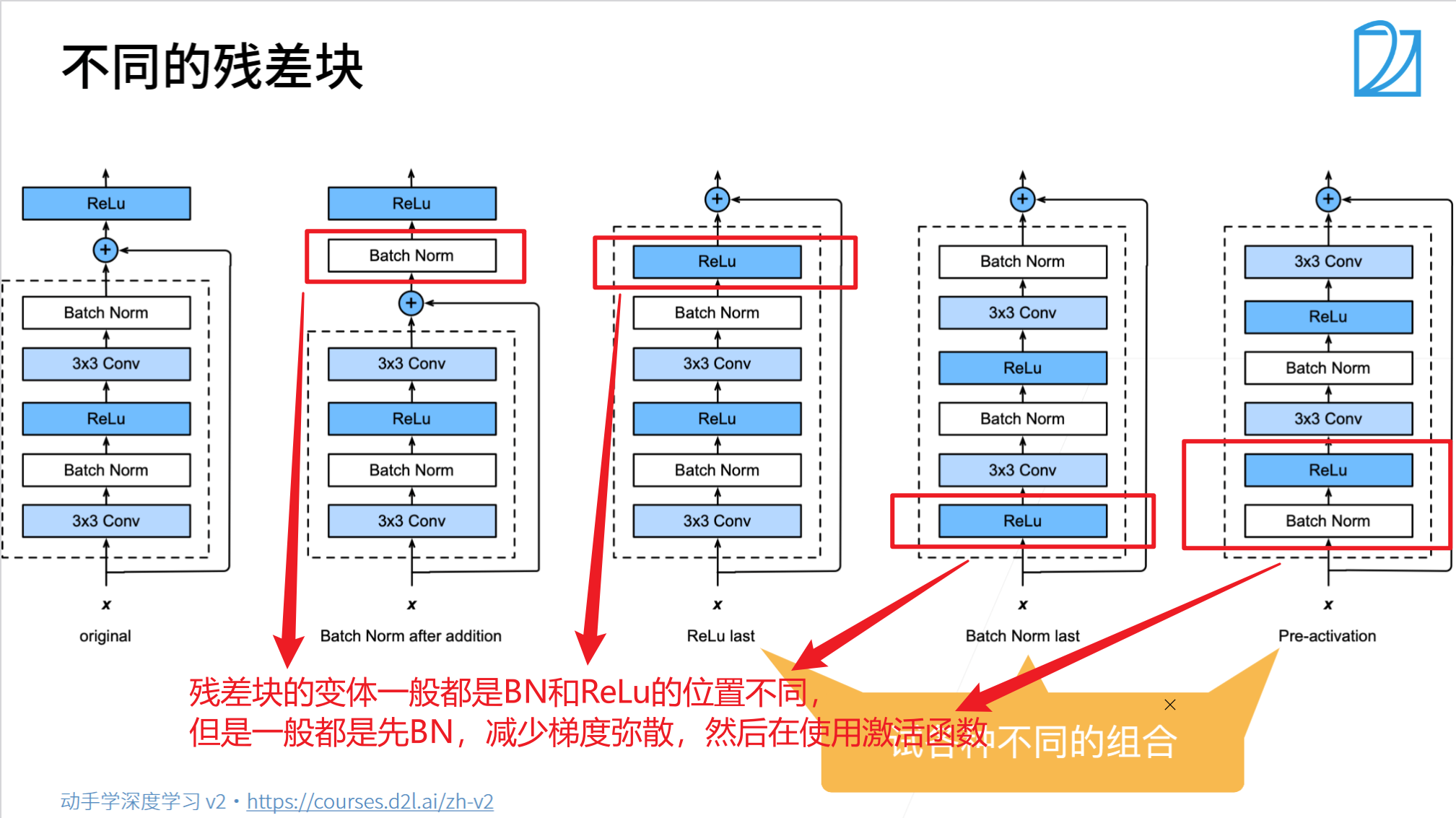
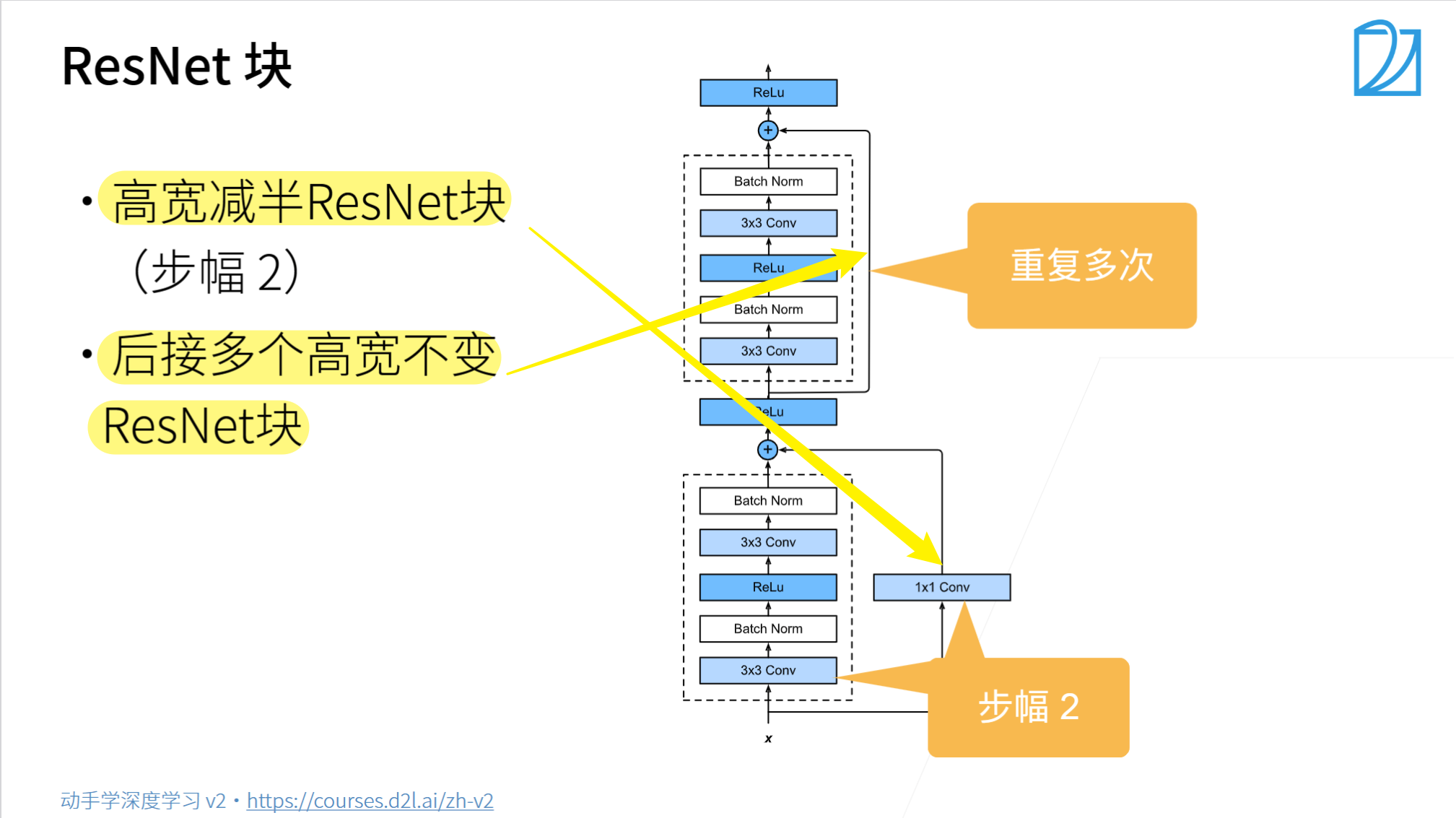
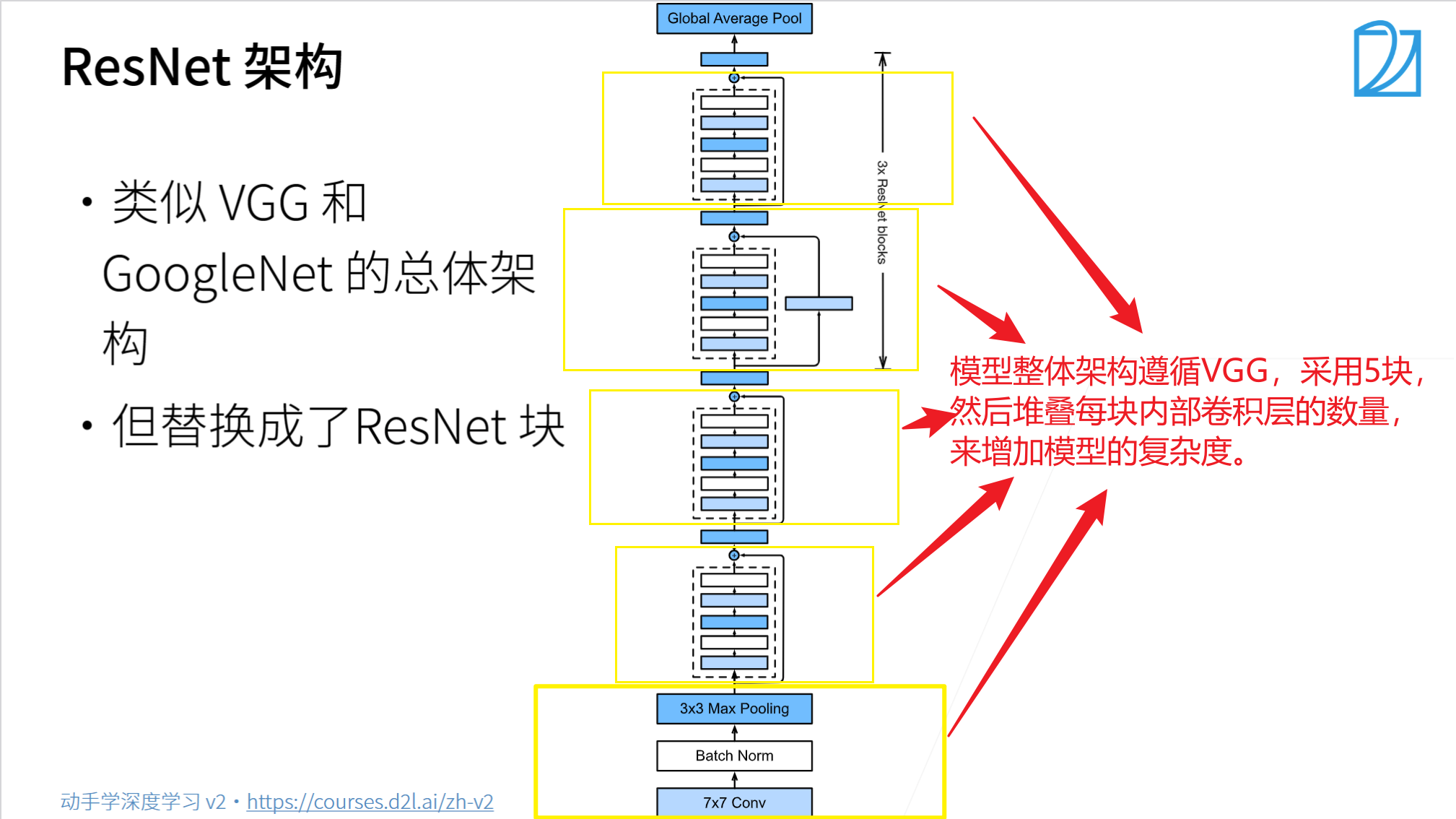
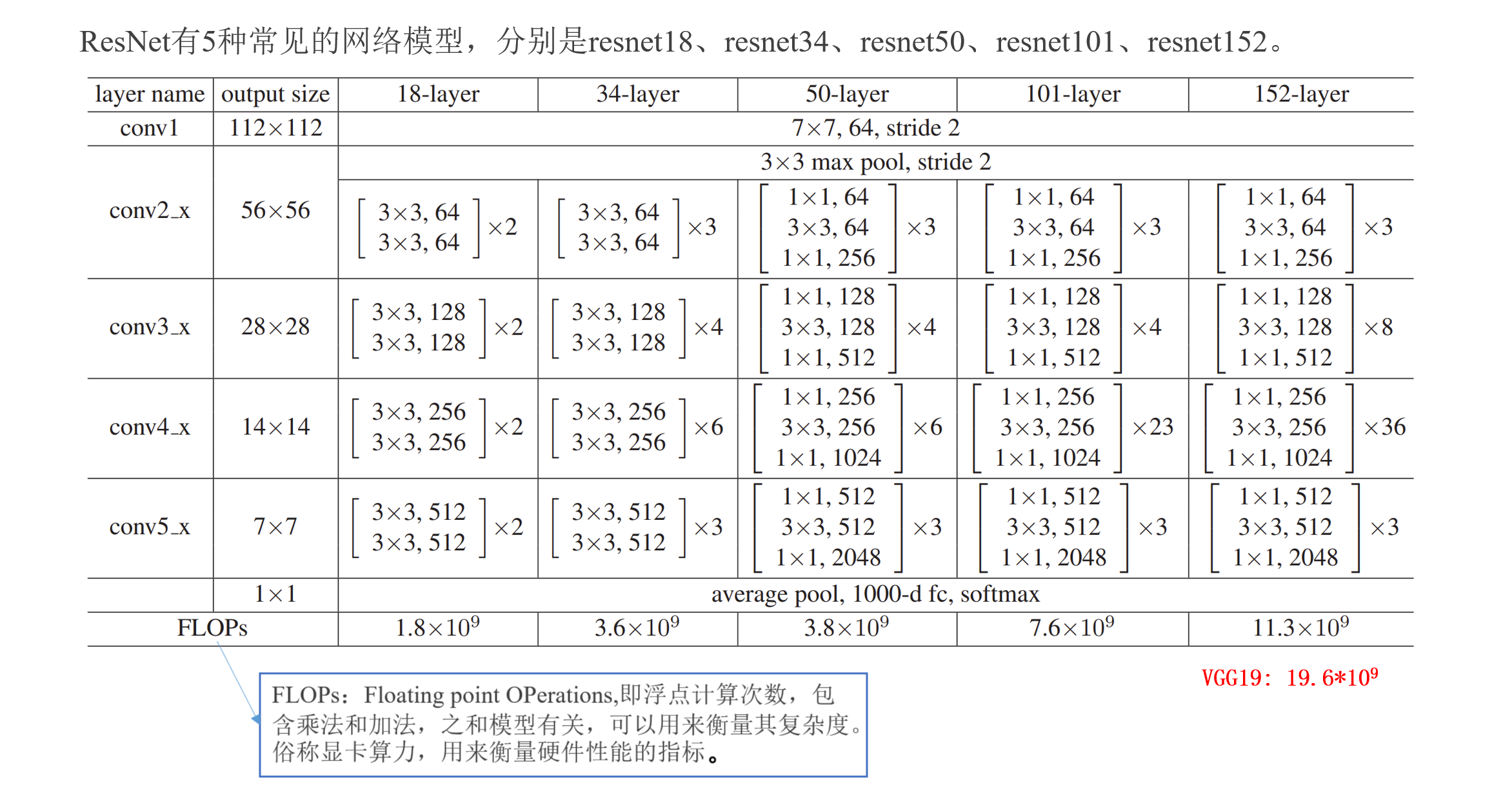
總結
- 殘差塊使得很深的網(wǎng)絡更加容易訓練
- 甚至可以訓練一千層的網(wǎng)絡
- 殘差網(wǎng)絡對隨后的深層神經(jīng)網(wǎng)絡設計產(chǎn)生了深遠影響,無論是卷積類網(wǎng)絡還是全連接類網(wǎng)絡。
ResNet代碼實現(xiàn)
- 導入相關庫
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
- 定義網(wǎng)絡模型
# 定義基本殘差塊
class Residual(nn.Module):def __init__(self, input_channels, num_channels, use_1x1conv=False, strides=1):super().__init__()self.conv1 = nn.Conv2d(input_channels, num_channels, kernel_size=3, padding=1, stride=strides)self.conv2 = nn.Conv2d(num_channels, num_channels, kernel_size=3, padding=1)if use_1x1conv: # 是否需要降低空間分辨率,增加通道維維度self.conv3 = nn.Conv2d(input_channels, num_channels, kernel_size=1, stride=strides)else:self.conv3 = Noneself.bn1 = nn.BatchNorm2d(num_channels)self.bn2 = nn.BatchNorm2d(num_channels)self.relu = nn.ReLU(inplace=True)# inplace為True,將會改變輸入的數(shù)據(jù) ,否則不會改變原輸入,只會產(chǎn)生新的輸出。# 產(chǎn)生的計算結果不會有影響。利用in-place計算可以節(jié)省內(nèi)(顯)存,同時還可以省去反復申請和釋放內(nèi)存的時間。但是會對原變量覆蓋,只要不帶來錯誤就用。def forward(self, X):Y = F.relu(self.bn1(self.conv1(X)))Y = self.bn2(self.conv2(Y))if self.conv3:X = self.conv3(X)Y += Xreturn F.relu(Y)
查看普通殘差塊:輸入和輸出形狀一致
blk= Residual(3, 3)
X = torch.rand(4, 3, 6, 6)
Y = blk(X)
Y.shape

查看升維殘差塊:增加輸出通道的同時,減半輸入的高和寬
blk = Residual(3, 6, use_1x1conv=True, strides=2)
X =torch.rand(4, 3, 6, 6)
Y =blk(X)
Y.shape

# 定義resnet塊
def resnet_block(input_channels, num_channels, num_residuals, first_block=False):"""定義大的殘差塊(5塊)"""blk = []for i in range(num_residuals):if i == 0 and not first_block:# 除了一個塊,每個塊的一個升維殘差塊,要先縮小輸入特征圖的尺寸,增大通道數(shù)blk.append(Residual(input_channels, num_channels, use_1x1conv=True, strides=2))else:# 第一塊或者每塊中用于提取特征的堆疊的基本殘差塊,輸入和輸出的形狀一致blk.append(Residual(num_channels, num_channels))return blk
# 定義ResNet網(wǎng)絡模型
b1 = nn.Sequential( # 輸入形狀:[1, 1, 224, 224]nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3), # (224 - 7 + 2*3)/2 + 1 = 112nn.BatchNorm2d(64), nn.ReLU(), # [1, 64, 112, 112]nn.MaxPool2d(kernel_size=3, stride=2, padding=1) # [1, 64, 56. 56]
)
b2= nn.Sequential(# *列表:表示解包操作,把列表元素順序展開# *[1, 3, 2 , 5, 4] = 1, 3, 2, 5, 4*resnet_block(64, 64, 2, first_block=True) # [1, 64, 56, 56]、[1, 64, 56, 56]
)
b3 = nn.Sequential(*resnet_block(64, 128, 2) # [1, 128, 28, 28]、[1, 128, 28, 28]
)
b4 = nn.Sequential(*resnet_block(128, 256, 2) # [1, 256, 14, 14]、[1, 256, 14, 14]
)
b5 = nn.Sequential(*resnet_block(256, 512, 2) # [1, 512, 7, 7]、[1, 512, 7, 7]
)
net = nn.Sequential(b1,b2,b3,b4,b5,nn.AdaptiveAvgPool2d((1, 1)), # [1, 512, 1, 1]nn.Flatten(), # [1, 512*1*1]= [1, 512]nn.Linear(512, 10) # [1, 512] --> [1, 10]
)
- 查看網(wǎng)絡模型
X = torch.randn(1, 1, 224, 224)
for layer in net:X = layer(X)print(layer.__class__.__name__, 'output shape:\t', X.shape)
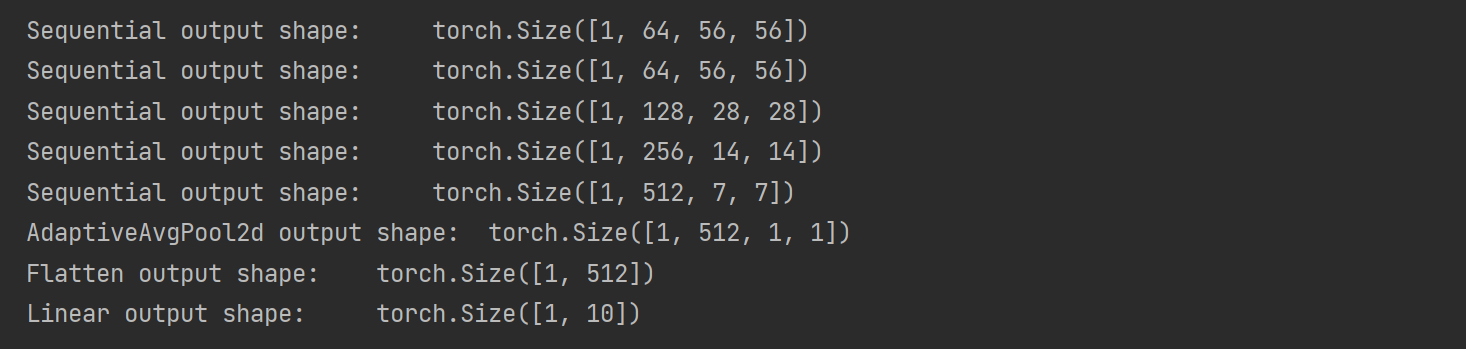
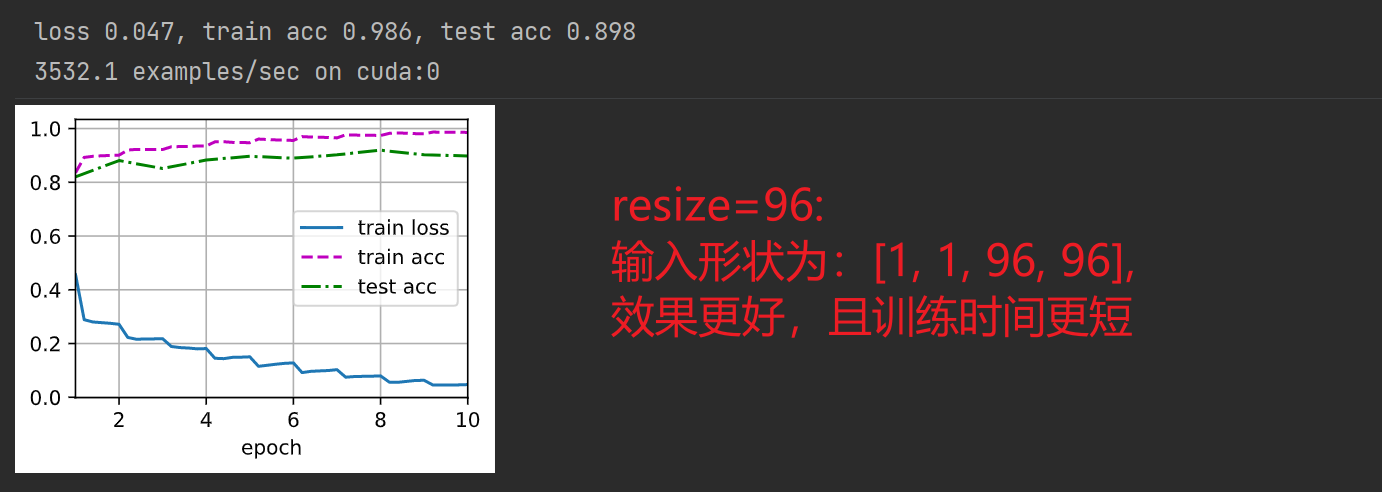
- 加載數(shù)據(jù)集
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
- 訓練模型
lr, num_epochs = 0.05, 10
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
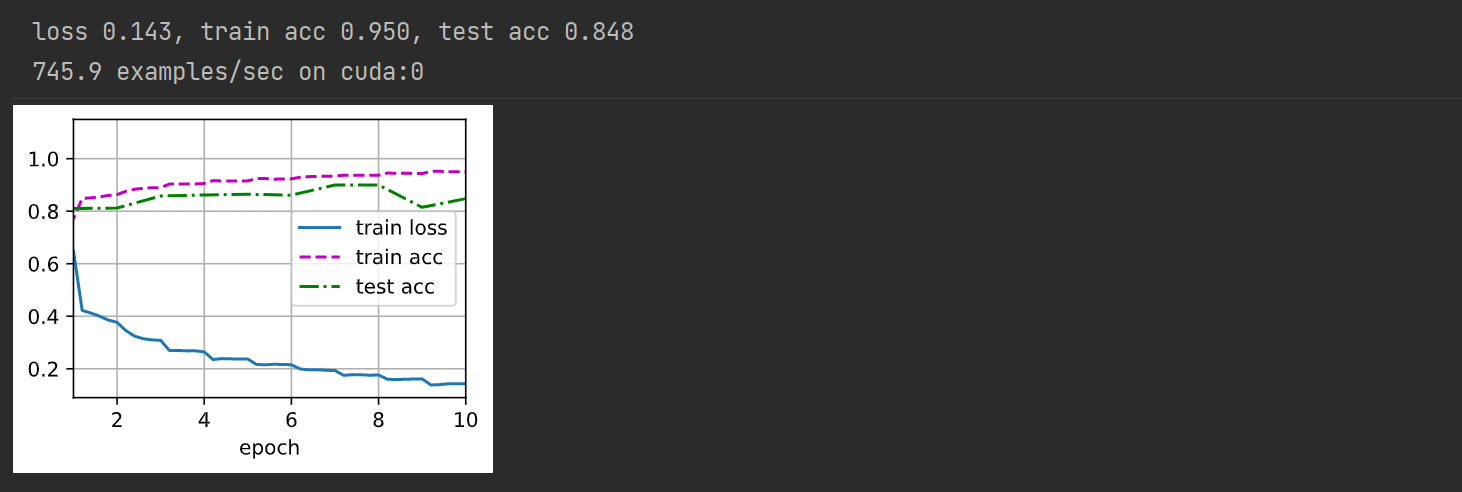
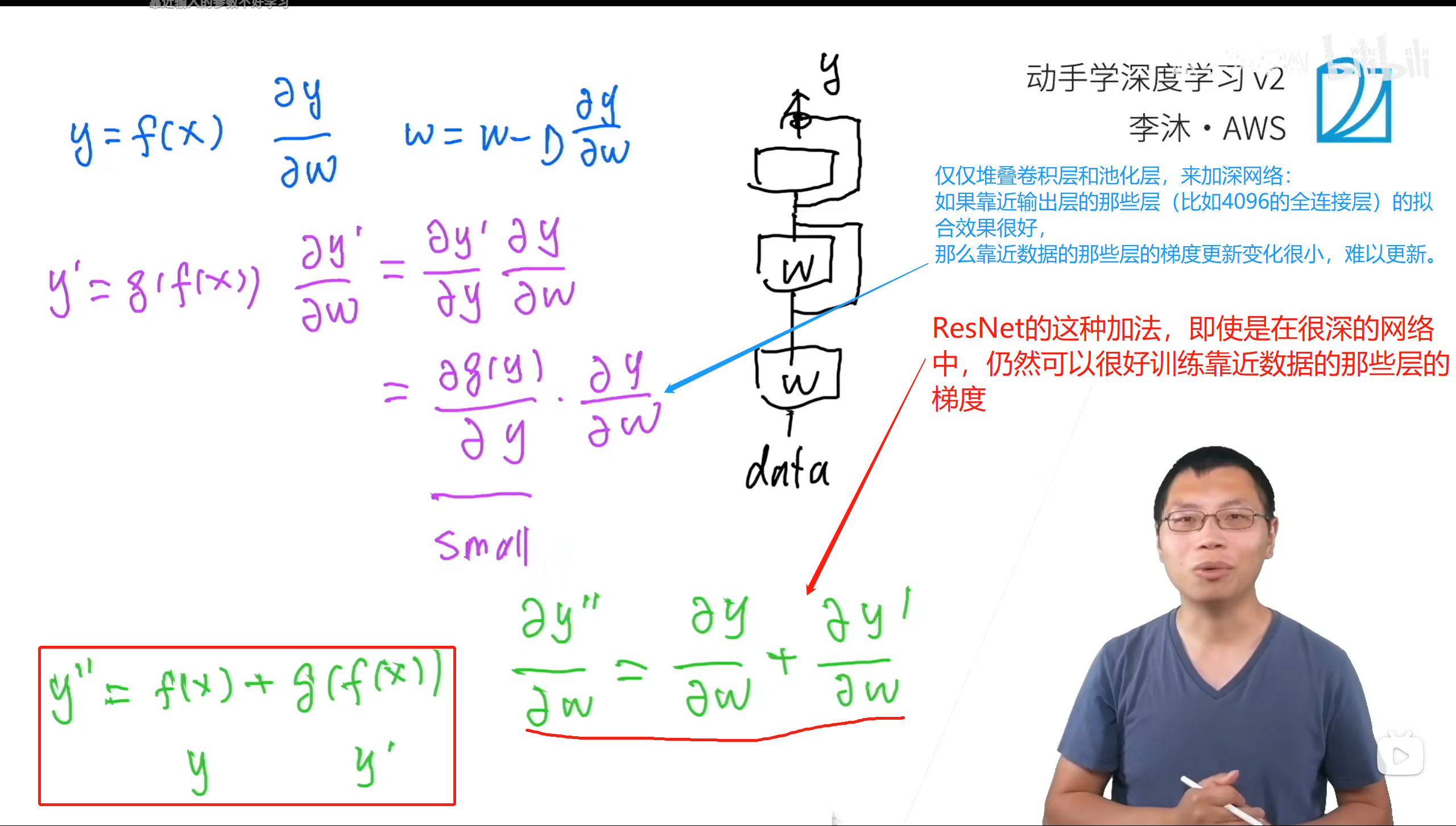
ResNet的梯度計算
QA
- 學習率也可以讓靠近輸出(標簽)的小一些,靠近輸入(輸入)的大一些,來緩解梯度消失的問題